
导 语: 认为只有硅基机器才能进行计算是一个常见误解。事实上,使用不同形式的物质,如生命物质,也可以实现其他形式的计算。利用理论计算机科学和合成生物学之间的协同效应,创建强大的细胞计算机(cellular computer),可以超越图灵计算。
研究领域:生物计算,细胞计算机,算法复杂性,合成生物学,复杂系统
理论计算机科学和生物学几十年来一直相互借鉴启发。计算机科学试图模仿生物系统的功能以发展计算模型,包括自动机、人工神经网络和演化算法,而生物学则将计算作为一种隐喻来解释生物系统的功能。[4] 例如,自上世纪70年代初,生物学家就使用布尔逻辑来概念化基因调控,当时雅克·莫诺(Jacques Monod)撰写了这样一句富有启发性的声明:“……就像计算机的运作方式一样。”[40]
本文认为信息处理是计算机科学和分子生物学之间的纽带。信息及其处理位于这两个领域的核心。在计算机科学中,诸如有限状态机或图灵机之类的计算模型定义了如何从一组输入和一组规则或指令生成输出。同样地,生物系统(如图1A中的细菌细胞)感知并对输入刺激做出反应,根据其内部配置生成响应。通过使用合成生物学[6],现在可以修改生物系统中每个步骤的具体性质(例如编辑活细胞的DNA以感知新的输入),从而实现使用生命物质编程信息处理设备。[9]这一激动人心的突破不仅为传统计算机无法达到的应用提供了可能性,还挑战了计算的传统概念以及可计算的内容。这一引人入胜的概念有可能将计算机科学带入新的领域,为未来的进步和发现铺平道路。
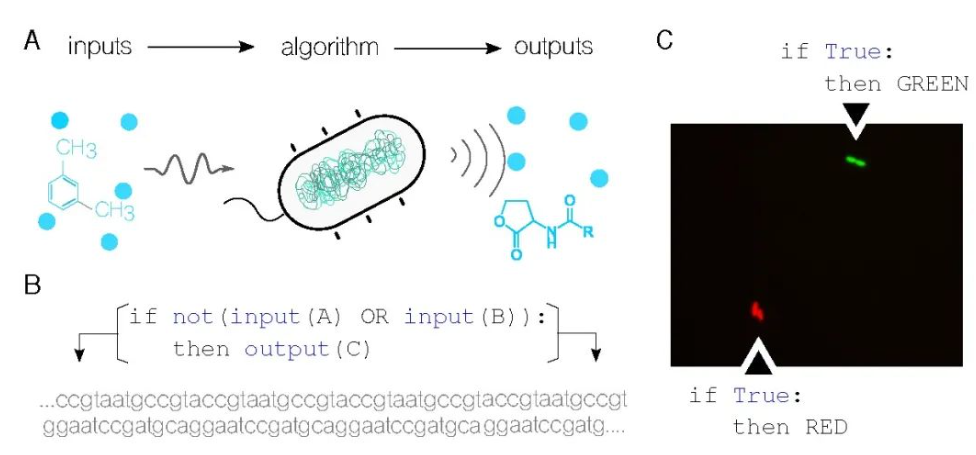
图1. 编程细菌执行生物布尔逻辑函数。A. 细胞具有感知各种物理化学输入并根据其DNA中编码的算法规则产生输出的能力。这种输入-算法-输出关系对计算概念至关重要。B. 组合布尔逻辑函数可以集成到细胞的基因组中。例如,假设A和B是两种化学输入信号,C是给定输出基因的表达产物,则函数如果¬(A ∨ B) 则 C 可以被编码成DNA序列,然后引入活细胞中。C. 在所示示例中,简单的逻辑语句在假单胞菌中实现,并使用荧光显微镜进行可视化。顶部的细胞被编程为无论输入是什么都表达绿色荧光蛋白,而底部的细胞被编程为产生红色荧光蛋白作为它们的输出。
编程生物系统与编程非生物系统存在根本性的差异,因为所使用的物理基质截然不同。与由人类设计和构建的传统技术不同,生物系统通过自然选择进化而来。这意味着我们用于编程传统技术的工具和方法是可预测且已知的,并且其功能的实现有明确的边界。然而,细胞、基因和分子等生物物质并非由我们人工构建,其运行规律尚未被完全揭示。尽管我们可以通过基因网络实现诸如布尔逻辑的简单计算模型,但更复杂的计算仍然面临挑战。为了推动高级生物计算的发展,我们需要不断深化对分子系统动力学的理解,并发展更适用于生物系统的新型计算理论,超越传统的图灵机计算模式。
分子生物学的最新进展极大地推动了生物计算的发展,该领域的进展可分为四个关键阶段。最初,在20世纪90年代初,理论进步和概念思想主导了该领域的发展[17],因为当时实验所需的技术尚未就位。随后是一段发展时期,直到20世纪90年代末,分子生物学和生物计算都取得了显著进展,促成了DNA计算的首批实验。1994年,Leonard Adleman 进行了一项具有标志性意义的实验,通过使用分子操作和DNA链解决了一例哈密顿路径问题(Hamiltonian path problem, HPP)。[3] 第三阶段发生在20世纪90年代末和21世纪初,随着合成生物学的出现,允许在细菌中实现逻辑门、开关和反馈环路。[1,2,3]第四阶段从2000年代末开始,克隆和DNA合成技术取得了显著进步,使得精确遗传构建的创建成为可能。[39]值得注意的是,现在理论发展落后于实验能力,这与20世纪90年代之前的情况截然相反。这一转变强化了本文的核心观点:理论计算机科学和(合成)生物学的交叉融合,为解锁新的可能性提供了独特的机会。
在最近一篇论文中,我们创造了“细胞优越性”这一术语[29],来指代实现在特定任务上能够胜过经典计算机的细胞计算机——这是一个与量子优越性(quantum supremacy)类似的概念。这些任务不太可能属于硅基计算机擅长的领域,特别是在高效解决数学问题方面。然而,存在一些经典计算机几乎无法发挥作用的领域。例如,考虑一个决策问题,评估两种环境污染物x和y的组合对植物生态系统造成的危险。在这种情况下,生活在该生态系统内的细胞计算机可以提供解决方案,并且更重要的是,如果答案是肯定的,它还可以为植物提供补救措施。这样的计算设备具有适应环境条件并将自身复制成更多类似功能的额外优势。类似的例子在其他领域也可以轻易找到,比如解决医疗问题。
本文对构建细胞计算机的基本概念进行分解,并提出了令人兴奋的改进方法。
1. 实现基本布尔函数
自合成生物学出现以来,实现布尔逻辑函数已成为生物计算的主要焦点。这是有道理的,因为在任何给定时间内,单个基因都可以是活跃的(即被表达)或非活跃的,从而使我们能够抽象出两个值:开/关或1/0。此外,从实验分子生物学角度来看,这个过程相对容易,并且技术是随时可获取的。[41]因此,实现新颖的生物组合指令的基础是什么呢?
生物系统中信息的定义是一个持续争论的话题。[2,44]为简单起见,我们假设非活跃信息以基因的形式存储在DNA中。换句话说,细胞正常功能所需的功能被编码进基因序列中,但这些功能在被表达之前保持非活跃。值得注意的是,这个生物信息的概念——即对生物系统有用的信息——与DNA数据存储领域中信息的定义不同。[16]在DNA数据存储中,目标是将非生物信息(即对任何生物系统都没有用的信息)编码进基因序列中,利用DNA作为替代存储设备。在这里,我们特指前者的定义。
当一个基因被表达时,会产生蛋白质,执行信息中编码的功能。换句话说,除非被表达,否则基因不会执行其功能。基因表达遵循布尔方法,基因可以根据需要打开和关闭。例如,编码功能C的基因只有在特定输入A和B结合时才会被激活,如图1B所示。在这个过程中,所有变量都可以被大幅修改:输入、输出以及处理它们的算法规则都可以被定义。
图1C展示了迄今为止在土壤细菌假单胞菌中实现的最简单逻辑程序。[22]这张使用荧光显微镜拍摄的图像展示了生长中的细胞——在拍摄照片时,实验开始时的两个单细胞最终分裂成四个。顶部的细胞发出明亮的绿色信号,这是由于它们正在表达的绿色荧光蛋白,底部的细胞产生红色荧光蛋白。这两组细胞遵循相同的逻辑程序,即无论输入如何,输出都应该被表达(在这种情况下,没有定义输入,这使其成为一个真语句)。值得注意的是,这个程序被编码进DNA序列中,没有在野生生物体中自然发现。相反,它已经被人为添加到它们的基因组中。
自20世纪90年代末以来,研究人员一直在细菌[54]、酵母[15]和哺乳动物细胞[7]中实现遗传的 NOT 逻辑函数和其他布尔逻辑门。多年来,这些实现方式已经以各种方式得到改进。例如,门被设计得更模块化,以便它们可以连接在一起构建更大的遗传电路。它们也变得更加标准化和更好地表征,使设计过程更加自动化。此外,科学家探索了各种细胞机制,以扩展用于构建这些门的工具包,包括反转酶、转录后反应,甚至是细胞群体[26,46]而不是单个细胞。将细胞计算机的计算能力与生物系统的潜力进行比较是很有趣的。在细胞中能够实现的一个相当大但合理的逻辑函数可能需要6到8个基因,而大肠杆菌细胞有4000多个基因。这表明我们只是刚刚开始解锁生物系统的计算能力。尽管如此,在生物细胞中设计和实现布尔逻辑函数如今已经成为常规过程。
然而,与有限状态机或图灵机相比,组合逻辑是一种有限的计算模型。而生物系统在信息处理方面还有更多可提供的。那么,还有哪些模型已经实现了?还有哪些模型有待探索?
2. 计算的生物模型
计算模型是一种理论概念,帮助我们了解在特定条件下可以解决什么问题以及如何解决。它们对于现代由电力驱动的硅基计算机的发展至关重要。然而,在生物计算中,我们需要以不同方式来处理事物:生物体进化出了自己的算法,我们必须弄清楚它们如何以与人造机器明显不同的方式处理信息。这一挑战涉及从基因网络与电子电路的比较,延伸到大脑过程与微处理器的比较。[31]
尽管我们对此的理解尚不全面,但我们拥有广泛的生物语言原语——这是软件领域中指代简单功能元素的术语——可以用来构建计算设备。尽管在生物细胞中实现比简单的布尔逻辑更复杂的计算模型是罕见的,但研究人员在这一领域已经取得了进展。一个有希望的研究方向是构建状态机,这些设备能够在特定输入的响应下,在有限数量的状态之间进行转换。
最早的这种机器之一是基因切换开关[23],于2000年在大肠杆菌中构建。这个开关有两个稳定状态,标记为A和B,如图2A所示,以及两个输入,I1和I2,可以在这两种状态间切换基因设备。每个状态使用不同的表达系统实现(即一个基因和其他所需序列),输入是可以根据需要外部添加的小分子。从那时起,基因切换开关已经有许多版本和优化,以及关于如何提高其性能的理论研究。[42]
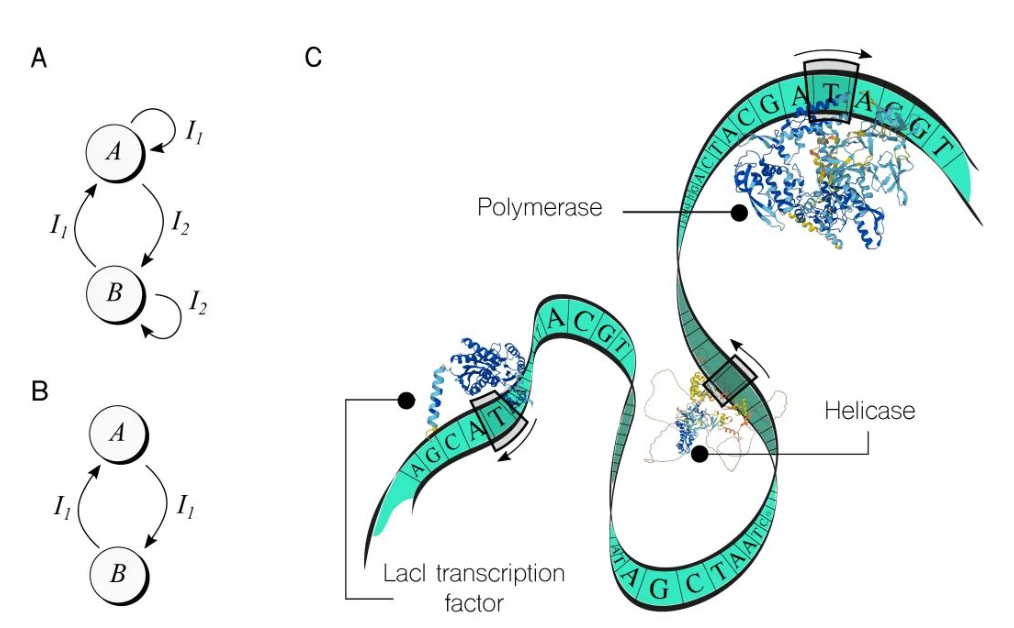
图2. 在细胞计算中实现计算模型,超越组合逻辑。A. 超越简单的布尔逻辑,探索像有限状态机这样强大的计算模型。例如,基因切换开关使用两种化学输入(Ix)在稳定状态A和B之间切换,如示意图所示。B. 使用仅一个输入来改变状态的基因开关更具挑战性,但已经有了示例。C. 想象DNA序列是一种类似纸带的数据存储,可以被图灵式计算系统中的酶读取和处理。尽管这个系统尚未完全被理解,也没有被形式化为计算设备,但它为揭示生物系统真正的信息处理能力提供了激动人心的可能性。在这一背景下,一个值得注意的例子是将这样一个酶催化装置概念化为能够执行逻辑可逆函数的计算系统[10],这一方法最近已经经历了实验分析。[50](这里是用AlphaFold生成蛋白质结构 https://alphafold.ebi.ac.uk))
另一个值得注意的例子是推开-推关开关,如图2B所示,也在大肠杆菌细胞中实现。[34]这种状态机只需要一个输入信号就能在不同状态之间转换,尽管通过添加额外的控制信号增加了实现的复杂性。因此,细胞对一个外部刺激做出了开关响应。
更具冒险精神的生物计算尝试超越传统模型,利用遗传物质实现受神经启发的架构,[33]创建了能够使用模糊逻辑和可逆性解决问题的人工神经网络和感知机[43]的生物版本,这些方法虽然取得了成功,并且可能更接近自然算法,但可能还有许多其他计算的生物模型有待发现。事实上,一些研究人员提出想法,利用生物过程超越图灵机的局限性,[36]尽管这种系统尚未实际实现。
想象DNA是一个图灵机。在这种类比中,DNA就像图灵机中的无限纸带,上面写着符号。然而,在DNA的情况下,纸带仅限于四种符号:A、C、G和T。有许多头部(酶)沿着纸带双向滑动,读取、写入和执行其他任务——模拟多头图灵机。这些头部独立且异步工作,它们的行为取决于特定规则或指令,这些规则或指令对每个头部都是独特的。此外,它们不仅沿着DNA滑动,还会从中分离,扩散到细胞体中,然后重新结合到纸带上并继续滑动。
在图2C中,一幅卡通将DNA序列描绘成一个图灵机。图中展示了来自生物系统中众多可用头的三种特定类型。例如,聚合酶是一种酶,它读取DNA,直到识别到特定字符串,然后生成一个与接下来的符号对应的RNA分子,直到遇到停止字符串,这个过程称为转录。解旋酶是另一种类型的“头”,它识别一个称为复制起点的字符串,然后帮助招募其他细胞机器复制 DNA,从而导致图灵机类比中的两个纸带。图2C中显示的第三种头是LacI转录因子(TF)。转录因子是合成生物学工具包的关键部分,[27]用于触发或阻止合成基因的行动,并通过一系列功能性基因设备传播开/关模式。
这种生物图灵机的一个有趣方面是,它的大部分元素都可以被编程。例如,纸带上的符号可以被编辑,转录因子的存在或缺失可以被调节,甚至非数字化的随机数量,这导致了模拟[19]和神经形态[47]计算方法的出现。管理各种“头”(如聚合酶)的规则也可以被编辑。例如,聚合酶可以被设置为依赖于特定输入组合,这已经将这个“头”包含在计算之中。
虽然将DNA视为图灵机的概念确实引人入胜,但这仍然是对生物系统复杂性的过度简化。然而,这种类比为理解生物体的计算能力以及如何设计它们执行特定任务提供了一个有用的框架。例如,通过研究生物体的生物机制,我们可以发现新的计算模型,这些模型可以用来构建可能比当前硅基计算机表现更好的细胞计算机——朝着细胞优越性的方向。[29]
到目前为止,本文侧重于计算机科学并从软件角度看待其对信息的分析。然而,细胞计算不仅涉及软件,还涉及修改生物体的物理实现,涉及硬件问题,因此也涉及工程领域。[5]
3. 硬件,软件,或者都不是
关于硬件或软件哪种提供更好的概念框架来形式化生物系统性能的辩论仍在进行中。[18]然而,值得注意的是,合成生物学在构建基因设备时倾向于工程和建筑类比。因此,硬件类比通常占据主导地位,创造了一个电气工程叙事,偏离了计算甚至计算工程。
虽然数学布尔函数和逻辑门的实现有许多相似之处,但后者根植于电气工程领域,该领域为生物计算提供了有用的概念和抽象,但同时也具有误导性。例如,将工程作为生物计算的框架,引发了操纵演变的物理结构的问题。与硬件不同,生物物质——或称为湿件——会根据不断变化的环境进行适应和突变。这带来了一个重大挑战,接下来将对此进行讨论。虽然有许多基因构建模块(即表达系统和分子连接)可以排列组合以构建更大的电路,但它们缺乏标准化和正交性,这是电子系统的一个关键特征。尽管已经在努力标准化湿件[8,38],工程可能仅仅是一个(非常)有用的概念。因此,将焦点放在实际信息流动上,从输入到输出,可能提供一个更适合操纵生物系统的框架。例如,基因逻辑门不遵循电子设备中常见的输入/输出标准,如TTL或CMOS,每个逻辑门都可能呈现不同的输入/输出模式。描述每个门的动态范围是识别兼容门的唯一方法。此外,遵循工程拓扑原则,基因电路通常是按顺序排列的,就像它们的电子对应物一样。然而,自然遗传网络中富含冗余和反馈环路,这可能具有算法优势(即从输入到输出更好的方法),超越直觉的前向设计。[30]
认为只有基于硅基机器才能进行计算是一个常见误解。事实上,这些只是数学形式化的特定实现。实际上,使用不同形式的物质,如生物物质,也可以实现其他形式的计算。
在细胞计算的世界中,我们可以在概念上区分硬件和软件的两种细胞计算方法。第一种方法涉及分布式细胞计算,[24,26,46]利用细胞群体来实现给定功能。群体中的每个细胞执行特定的逻辑功能,然后将其作为输入传递给其他细胞。这样可以将功能分解为多个部分,并分配给多个细胞,细胞本身充当硬件结构,而遗传程序则充当软件。通过将功能分解为多个部分并分配给细胞,可以更好地管理和扩展计算负担,因为细胞具有有限的资源和能量。第二种方法是可重配置性[25],涉及可以实时重新配置的基因设备。例如,一个基因程序能够根据控制信号,在任何时候执行多个预定义逻辑功能中的一种。[13]这种方法更接近我们对软件的理解——因为可重新配置的硅基硬件仍然是一个挑战——并且使设备更加灵活和适应性强,其功能可以根据需要进行更改。
除了涉及明确操纵基因和细胞组件以创建新型生物电路的自下而上方法之外,该领域还探索了自上而下的方法。[45]这些策略旨在通过改变输入刺激而不需要修改系统本身来理解和调节原生系统。它们已被应用于阐明关键的生物计算功能,如记忆,[11]这允许重新编程控制策略而无需调整基础生物硬件,这一想法让人联想到软件的利用。
在生物计算领域,很容易陷入硬件与软件的辩论中。因为这确实是一个重要的概念区别。虽然两者都具有独特的优势,但事实是,生命系统是独一无二的。它们既不是硬件也不是软件——至少不是我们定义的那样——而是理论计算生动展现的卓越例证。
4. 复杂性的故事
当涉及到细胞计算时,计算机科学和复杂系统分析交汇在一起,然而找到共同基础是一个重大挑战。一方面,计算机科学涉及算法复杂性和解决问题的困难。然而,硬件复杂性并不是一个主要关注点,因为计算机的物理系统是可预测的,没有意想不到的属性。另一方面,复杂性理论应用于分析复杂系统,如活细胞,涉及到由组件之间的相互作用产生的涌现特性和非线性特性[51],这些系统由于对其动态性能完全理解的不足而不可预测。
生物计算涉及处理这两个领域,但它们的交集仍然不明确。一个细胞是一个复杂系统,为计算设计基因设备需要考虑可以解决的问题和解决方案的复杂性。
从复杂系统的角度来看(图3A),需要注意的是,一个遗传程序的DNA序列并不是影响特定性能实现的唯一因素。各种层次增加了复杂性,包括将合成序列放置在细胞内染色体位置,这可能会对原始功能引入非线性变化。此外,携带程序的细胞底盘,以及物种和菌株,都可以改变原始程序。这就是我们所说的上下文依赖性[53]——一个描述这个问题的软件工程术语。此外,细胞不是孤立运作的,建立具有复杂结构和相互作用的种群也将修改原始程序。最后,生态环境将为程序的性能引入动态变化,这些变化很难提前预测。[49]如果生物计算设备旨在解决与环境相关的问题,后一级别尤为重要。尽管系统复杂性对生物计算提出了巨大挑战,但应强调这个挑战并非不可逾越。生命系统经过数百万年的演化,以惊人的精度高效地执行任务,同时管理复杂性。当然,这并不意味着人类可以达到相同水平来操纵生命物质,但我们肯定可以比目前做得更好。
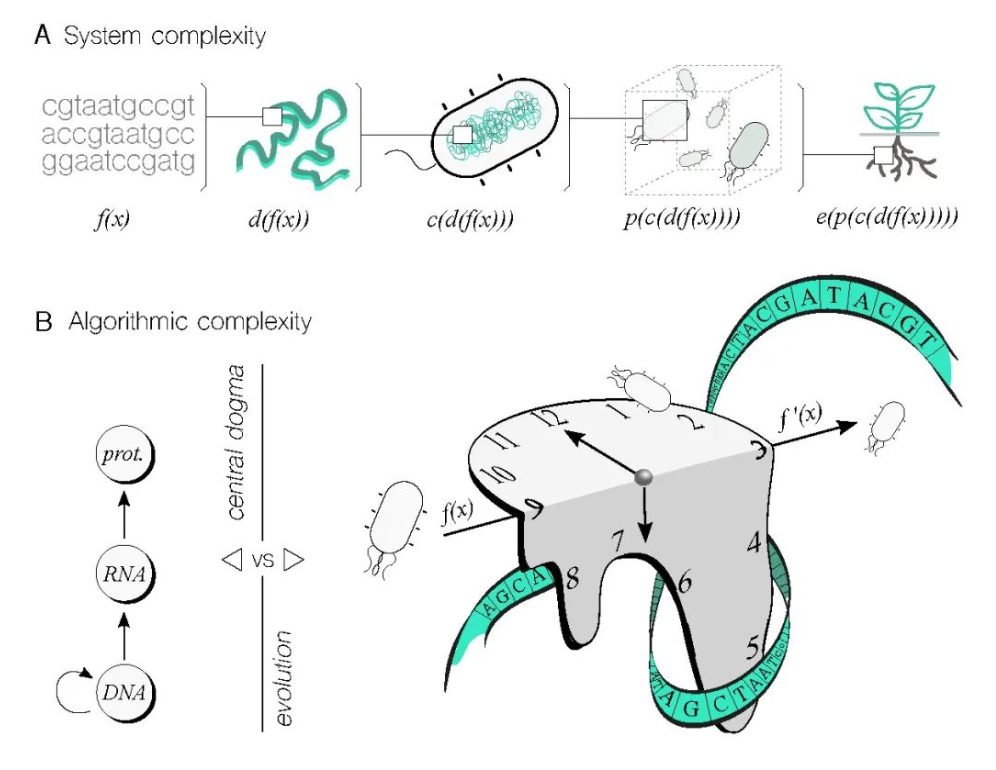
图3. 在复杂系统和计算机科学中寻找系统和算法复杂性之间的共同基础。A. 活细胞是具有涌现特性的复杂系统,这些特性由组成部分之间的相互作用导致。为了在DNA序列中实现功能,需要考虑不同层次的这些相互作用,以预测生物计算设备的性能。如图所示,编码到 DNA中的函数 f(x) 可以通过基因组位置、宿主生物体、种群动力学和生态位等因素进行修改,所有这些因素都增加了函数性能的复杂性。B. 算法复杂性对于任何计算工作都至关重要,也适用于不同的生命过程。尽管分子生物学的中心法则(从DNA到RNA再到蛋白质)是一个相对直接的过程,但进化(这里用达利的融化时钟来表示)具有更复杂的信息处理能力。一个函数可以通过以开放方式适应不断变化的环境而演变成新的函数,这给表征(以及最终利用)算法复杂性提出了重大挑战。
生物计算设备的算法复杂性值得更多关注,因为这是计算机科学中的一个核心话题。这涉及回答一个问题:在特定生物系统中,给定输入,获得输出有多困难?用于解决这个问题的常见度量标准包括时间和空间需求。在这种情况下,如果一个生物系统达到输出所需的时间比另一个长,那么前者至少在时间上被认为更复杂——这里假设输出保持不变,因为我们正在评估底层算法系统的复杂性。让我们将时间视为生物计算的有效度量标准,以阐明这里所要表达的观点。生物过程的复杂性可以直观地理解为在解决问题和提供解决方案方面具有不同级别(图3B)。例如,分子生物学的中心法则(CD)描述了基因表达过程(即,从DNA到蛋白质)涉及转录和翻译,这只能解决与DNA和表达所需的细胞机器存在的相关问题。通过将中心法则概念化为算法,我们可以检查完成它所需的时间。在理想化的转录级联情景中,其中一个节点的蛋白产物诱导级联中下一个基因的表达,时间将随级联长度线性增加。然而,这种时间复杂性肯定会受到反馈机制、分子非线性、资源分配和其他因素的影响而发生变化。
虽然基因表达是一个相对快速和简单的过程,但进化要复杂得多、曲折得多。进化可以解决更广泛的问题,但算法解决方案既不直接也不快速。生物系统通过进化适应环境特征,这作为一种算法是令人印象深刻的。通过突变和选择步骤精确计算演化过程的时间复杂性是一个重大挑战。然而,实现这一目标无疑将揭示隐藏的机制细节,从而极大地有益于生物计算工作。虽然演化计算受到自然演化的启发,但它并未完全捕捉其复杂性和开放性。因此,利用自然演化的复杂性来进行生物计算将是有益的。
许多当前的努力旨在克服演化对DNA程序的不可避免的影响,这可能导致突变和功能丧失。[48]然而,“受影响”这个术语可能会加剧问题,因为演化经常被负面看待,被视为破坏功能程序的过程。相反,将演化视为一种工具可以帮助DNA程序利用其信息处理能力,使性能超越当前限制。这样,演化可以成为一个宝贵的盟友,而不是一个障碍。
尽管达到全面理解系统复杂性(图3A)以至于掌握每一个细节似乎不太可能,但我们可以有效地将某些细节抽象为功能模块。这种方法使我们能够理解模块的输入输出动力学,而无需深入理解其内部运作。例如,遗传构建模块(图3A中的f(x))封装了许多机制细节,不是必须理解所有细节才能利用它们构建功能完全的基因逻辑门。
其他例子包括在不完全理解其上下文依赖性[53]的情况下使用基因逻辑门(图3A中的c(d(f(x))),或者即使对种群动力学不完全了解也能实现有效的多细胞分布计算[35](图3A中的p(c(d(f(x))))。此外,演化过程确实可以用于设计遗传电路的部分[56],即使对这些过程的完整描述可能难以捉摸。
总的来说,借用 Donella Meadows 的话,“我们无法控制[复杂]系统或弄清楚它们;但我们可以与它们共舞!”每一次对这些系统的新洞察都能实现更先进的生物计算,利用复杂性的机会仍然充足,即使我们并未完全理解它。
5. 挑战与机遇
改进细胞计算机的编程是一项具有挑战性的任务,需要加强理论计算机科学和合成生物学的交叉。例如,通过形式化新的计算模型,我们将增进对自然生态系统的理解,并增强合成遗传功能的范围。然而,基于生命动力学构建新的计算模型是困难的,因为我们习惯于当前基于硅的实现和现有的数学抽象。此外,理解系统和算法复杂性之间的重叠可以导致适用于生物物质的新型计算模型。
进化是另一个关键挑战,因为当前合成功能的实现往往避开了演化动力学,仅仅是因为我们不知道如何对其进行工程理解。[14,29]这在处理硬件机械导向的工程学科时尤为具有挑战性。然而,当与软件工程进行对比时,这种比较就不那么具有挑战性了。[12] 事实上,计算机科学可以支持这种观点,考虑到几十年前从生物学中获得灵感的演化计算,另一个有趣的方向是超越基因调控的工具箱。实际上,活细胞远不止于此。整合新陈代谢和其他细胞的过程可以导致更类似于活细胞实现关键生命过程的异形计算[28]。
发展细胞计算机不仅在学术上具有趣味性,而且在各个领域具有实际应用,从医学[55]到生态学[21],甚至是使用今天已经存在的相对简单的细胞计算机。这些应用领域提出了一套独特的问题类别,需要基于生物的解决方案。此外,诸如形态发生信息处理等经典探究,这在图灵[20]的研究中至关重要,如今是一个突出的领域,突显了发育生物学与信息处理问题之间的紧密联系。[37]这些特定挑战似乎更适合生物计算方法,而不是传统的计算方法。
未来将有更多挑战。尽管人类定义的细胞计算机能力的界限尚不清楚,但前景是光明的。例如,考虑微生物是无处不在的,并且对从我们的身体到环境生态系统等各个系统发挥着重要(和有益)作用。[21]美妙的机会在前方等待,它们围绕着如果系统失衡或崩溃时,重新编程这些微生物来帮助平衡系统。毫无疑问,生物计算是一个值得追求的有希望的研究领域。
参考文献
1. Abelson, H.et al. Amorphous computing. Commun. ACM 43, 5 (May 2000), 74–82.
2. Adami, C. The use of information theory in evolutionary biology. Annals of the New York Academy of Sciences 1256, 1 (2012), 49–65.
3. Adleman, L.M. Molecular computation of solutions to combinatorial problems. Science 266, 5187 (1994), 1021–1024.
4. Amos, M. and Goñi-Moreno, A. Cellular computing and synthetic biology. Computational Matter (2018), 93–110.
5. Andrianantoandro, E., Basu, S., Karig, D.K., and Weiss, R. Synthetic biology: New engineering rules for an emerging discipline. Molecular Systems Biology 2, 1 (2006), 2006.0028.
6. Ausländer, S., Ausländer, D., Fussenegger, M. Synthetic biology—the synthesis of biology. Angewandte Chemie Intern. Edition 56, 23 (2017), 6396–419.
7. Ausländer, S. et al. Programmable single-cell mammalian biocomputers. Nature 487, 7405 (2012), 123–127.
8. Beal, J. et al. The long journey towards standards for engineering biosystems: Are the Molecular Biology and the Biotech communities ready to standardise?EMBO Reports 21, 5 (2020), e50521.
9. Benenson, Y. Biomolecular computing systems: principles, progress and potential. Nature Reviews Genetics 13, 7 (2012), 455–468.
10. Bennett, C.H. The thermodynamics of computation—a review. Intern. J. Theoretical Physics 21, (1982), 905–940.
11. Biswas, S., Clawson, W., and Levin, M. Learning in transcriptional network models: Computational discovery of pathway-level memory and effective interventions. Intern. J. of Molecular Sciences 24, 1 (2022), 285.
12. Calcott, B. et al. Engineering and biology: Counsel for a continued relationship. Biological Theory 10, (2015), 50–59.
13. Canadell, D. et al. Implementing re-configurable biological computation with distributed multicellular consortia. Nucleic Acids Research 50, 21 (2022), 12578–12595.
14. Castle, S.D., Grierson, C.S., Gorochowski, T.E. Towards an engineering theory of evolution. Nature Commun. 12, 1 (2021), 3326.
15. Chen, Y. et al. Genetic circuit design automation for yeast. Nature Microbiology 5, 11 (2020), 1349–1360.
16. Church, G.M., Gao, Y., and Kosuri, S. Next-generation digital information storage in DNA. Science 337, 6102 (2012), 1628–1628.
17. Conrad, M. Molecular computing. Advances in Computers, 31 . Elsevier, 1990, 35–324.
18. Danchin, A. Bacteria as computers making computers. FEMS Microbiology Reviews 33, 1 (2008), 3–26.
19. Daniel, R., Rubens, J.R., Sarpeshkar, R., and Lu, T.K. Synthetic analog computation in living cells. Nature 497, 7451 (2013), 619–623.
20. de Lorenzo, V., Marliere, P., and Sole, R. Bioremediation at a global scale: from the test tube to planet Earth. Microbial Biotechnology 9, 5 (2016), 618–625.
21. De Lorenzo, V. et al. The power of synthetic biology for bioproduction, remediation and pollution control: the UN’s Sustainable Development Goals will inevitably require the application of molecular biology and biotechnology on a global scale. EMBO Reports 19, 4 (2018), e45658.
22. Espeso, D.R., Martçnez-Garcça, E., De Lorenzo, V., and Goñi-Moreno, Á. Physical forces shape group identity of swimming Pseudomonas putida cells. Frontiers in Microbiology 7, 1437 (2016).
23. Gardner, T.S., Cantor, C.R., and Collins, J.J. Construction of a genetic toggle switch in Escherichia coli. Nature 403, 6767 (2000), 339–342.
24. Goni-Moreno, A., Redondo-Nieto, M., Arroyo, F., and Castellanos, J. Biocircuit design through engineering bacterial logic gates. Natural Computing 10, (2011), 119–127.
25. Goñi-Moreno, A. and Amos, M. A reconfigurable NAND/NOR genetic logic gate. BMC Systems Biology 6, 1 (2012), 1–11.
26. Goñi-Moreno, A., Amos, M., and de la Cruz, F. Multicellular computing using conjugation for wiring. PLoS One 8, 6 (2013), e65986.
27. Goñi-Moreno, Á., Benedetti, I., Kim, J., and de Lorenzo, V. Deconvolution of gene expression noise into spatial dynamics of transcription factor–promoter interplay. ACS Synthetic Biology 6, 7 (2017), 1359–1369.
28. Goñi-Moreno, A. and Nikel, P.I. High-performance biocomputing in synthetic biology–integrated transcriptional and metabolic circuits. Frontiers in Bioengineering and Biotechnology 40, (2019).
29. Grozinger, L. et al. Pathways to cellular supremacy in biocomputing. Nature Commun. 10, 1 (2019), 5250.
30. Grozinger, L. and Goñi-Moreno, Á. Computational evolution of gene circuit topologies to meet design requirements. In Proceedings of the 2023 Artificial Life Conf. MIT Press, Cambridge, MA, USA.
31. Jonas, E. and Kording, K.P. Could a neuroscientist understand a microprocessor? PLoS Computational Biology 13, 1 (2017), e1005268.
32. Knight, T.F. and Sussman, G.J. Cellular gate technology. Massachusetts Inst of Tech Cambridge Artificial Intelligence Lab, 1998.
33. Li, X. et al. Synthetic neural-like computing in microbial consortia for pattern recognition. Nature Commun. 12, 1 (2021), 3139.
34. Lou, C. et al. Synthesizing a novel genetic sequential logic circuit: A push-on push-off switch. Molecular Systems Biology 6, 1 (2010), 350.
35. Macía, J., Posas, F., and Solé, R.V. Distributed computation: The new wave of synthetic biology devices. Trends in Biotechnology 30, 6 (2012), 342–349.
36. MacLennan, B.J. Natural computation and non-Turing models of computation. Theoretical Computer Science 317, 1–3 (2004), 115–145.
37. Manicka, S. and Levin, M. Minimal developmental computation: a causal network approach to understand morphogenetic pattern formation. Entropy 24, 1 (2022), 107.
38. Martínez-García, E. et al. SEVA 4.0: An update of the Standard European Vector Architecture database for advanced analysis and programming of bacterial phenotypes. Nucleic Acids Research 51, D1 (2023), D1558–D1567.
39. Meng, F. and Ellis, T. The second decade of synthetic biology: 2010–2020. Nature Commun. 11, 1 (2020), 5174.
40. Monod, J. Chance and Necessity: An essay on the natural philosophy of modern biology , 1971.
41. Nielsen, A.A. et al. Genetic circuit design automation. Science 352, 6281 (2016), aac7341.
42. Pájaro, M., Alonso, A.A., Otero-Muras, I., and Vázquez, C. Stochastic modeling and numerical simulation of gene regulatory networks with protein bursting. J. Theoretical Biology 421, (2017), 51–70.
43. Pandi, A.et al. Metabolic perceptrons for neural computing in biological systems. Nature Commun. 10, 1 (2019), 3880.
44. Pattee, H.H. and Rączaszek-Leonardi, J. How Does a Molecule Become a Message? LAWS, LANGUAGE and LIFE: Howard Pattee’s Classic Papers on the Physics of Symbols with Contemporary Commentary. Springer, 2012, 55–67.
45. Pezzulo, G. and Levin, M. Top-down models in biology: Explanation and control of complex living systems above the molecular level. J. The Royal Society Interface 13, 124 (2016), 20160555.
46. Regot, S. et al. Distributed biological computation with multicellular engineered networks. Nature 469, 7329 (2011), 207–211.
47. Rizik, L. et al. Synthetic neuromorphic computing in living cells. Nature Commun. 13, 1 (2022), 5602.
48. Sleight, S.C., Bartley, B.A., Lieviant, J.A., and Sauro, H.M. Designing and engineering evolutionary robust genetic circuits. J. Biological Engineering 4, 1 (2010), 1–20.
49. Solé, R.V., Montañez, R., and Duran-Nebreda, S. Synthetic circuit designs for earth terraformation. Biology Direct 10, 1 (2015), 1–10.
50. Srivastava, R. and Bagh, S. A logically reversible double Feynman gate with molecular engineered bacteria arranged in an artificial neural network-type architecture. ACS Synthetic Biology 12, 1 (2022), 51–60.
51. Stoof, R. and Goñi-Moreno, Á. Modelling co-translational dimerization for programmable nonlinearity in synthetic biology. J. Royal Society Interface . 17, 172 (2020), 20200561.
52. Tas, H., Grozinger, L., Goñi-Moreno, A., and de Lorenzo, V. Automated design and implementation of a NOR gate in Pseudomonas putida. Synthetic Biology 6, 1 (2021), ysab024.
53. Tas, H. et al. Contextual dependencies expand the re-usability of genetic inverters. Nature Commun. 12, 1 (2021), 355.
54. Wang, B., Kitney, R.I., Joly, N., and Buck, M. Engineering modular and orthogonal genetic logic gates for robust digital-like synthetic biology. Nature Commun. 2, 1 (2011), 508.
55. Xie, Z. et al. Multi-input RNAi-based logic circuit for identification of specific cancer cells. Science 333, 6047 (2011), 1307–1311.
56. Yokobayashi, Y., Weiss, R., Arnold, F.H. Directed evolution of a genetic circuit. In Proceedings of the National Academy of Sciences 99, 26 (2002), 16587–16591.











